

AIがもたらすマッチングの進化 ~「外部人事データ」と「内部人事データ」の自然言語解析とは~
石山 洸さん(株式会社リクルートホールディングス Recruit Institute of Technology 推進室 室長)
2016/09/30基礎、採用、石山洸、リクルートホールディングス、人工知能(AI)
外部人事データと内部人事データの掛け合わせで、AIの学習を加速させる

内部人事データについて教えていただけますか。
こちらの図をご覧ください。これは、人事周辺におけるデータと技術の関係をマッピングしたものです。
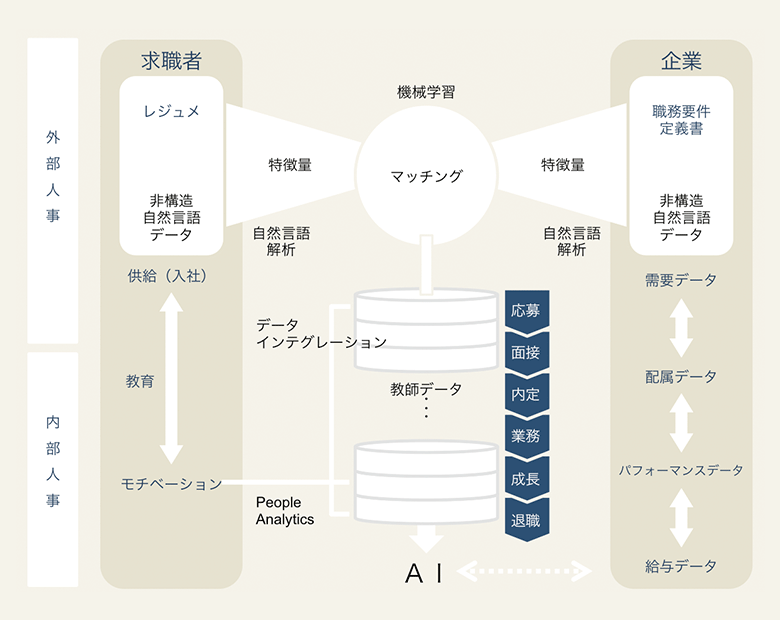
内部人事データとは、各企業が社内で保有している個人の入社後データのこと。最初にどこかの部署に「配属(部署・勤務地)」となり、そこでの「業務」において何らかの「成果」を出し、その成果は「人事考課・評価結果」となり、「給与・報酬」や「昇格(降格)」に繋がります。
ほかにも「定期面談」や「異動希望」、「業務日報」などのログを残している企業もあるでしょう。会社によっては退職時に「退職面談やアンケート」を行い、結果を保存していることもあります。
たしかに、人事は実に多くのデータを抱えていますね。
これら一連の内部人事データは人事システム上でフラグ立てされている場合もありますし、「人事考課コメント」や「面談結果」などはフリーテキスト(非構造の自然言語)として記録されている場合もあります。
このような内部人事データを、AIが外部人事データと掛け合わせて構造化・解析・学習していくことで、「この企業の、このポジションには、この人たちのマッチング度合いが高い」ということが、より高精度に分かるようになります。
また、そこに「パフォーマンス高く働いているか(企業の目線)」「モチベーション高く働いているか(本人の目線)」といった「マッチングが本当に良かったかどうか」を評価する内部人事データがさらにフィードバックされていくことで、より人工知能が賢くなっていきます。
この際、外部人事データと内部人事データの境界が徐々になくなっていき、データインテグレーションされて解析していくことがポイントとなります。
さらには、「会議の録音データ」「メールのやりとり内容やスケジューラの履歴」「議事録」といった、日常的に生まれ続けているデータの活用や、ウェアラブルデバイスなどを用いてデータ取得量を増やすことで、解析できることはさらに増えていきます。




