

人工知能によって「売れる営業トーク」「伝わる会社説明会」の
論理構造を可視化する(前編)
河野 理愛さん(コグニティ株式会社 代表取締役)
採用や育成、評価など、さまざまな場面で「伝える」ことが重要な人事の仕事。一方で伝え方の客観的な分析は難しく、明確な改善点が見えづらいものでもあります。
ところが近年、人工知能の活用によって、会話や講演の構成を解析する技術が生まれています。これによって、「講演における論理構成の可視化」や「売れる営業トークを解析する」といったことまで可能になっています。
前編では、この技術開発を行うコグニティ株式会社 代表取締役 河野理愛さんに、人工知能による解析のしくみと、その活用方法をうかがいました。

- 河野 理愛さん(カワノ リエ)
- コグニティ株式会社 代表取締役
1982年生まれ、徳島県出身。慶應義塾大学総合政策学部卒業。大学在学中の2001年にNPO法人を設立、代表として運営を行う。2005年にソニー株式会社入社。カメラ事業を中心に、経営戦略・商品企画に従事。2011年に株式会社ディー・エヌ・エー入社。ソーシャルゲームの海外展開を担当。2013年3月、コグニティ株式会社を設立。
「伝える」を可視化する技術を支える、独自の解析ルール

人工知能を活用し、会話や講演の内容を解析や可視化ができるそうですね。具体的にはどのようなことが可能なのでしょうか。
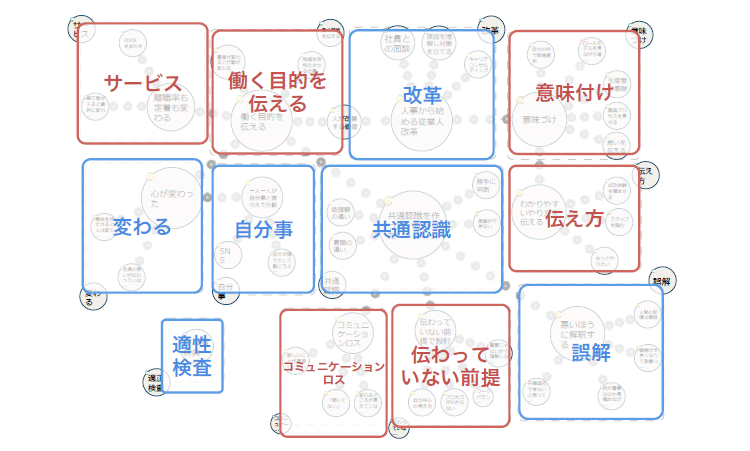
会話や講演に限らず、レポートや議事録など、ある程度の分量があり、パターンが見つけられるものであれば、書き言葉・話し言葉問わずに解析が可能です。私たちの論理構造解析技術では、それらの話題のまとまりやつながりを可視化し、重要なポイントや改善点を見つけ出すことができます。
これらの解析をもとに、弊社ではレポートを提供しています。このレポートでは、まず論点のまとまりや流れを示したうえで、どの部分が起点となる「重要論点」となっていたのか、または、内容としては重要だったにもかかわらず、詳しく語られていなかった「要検討論点」はどこであったのか、そしてそれらの内容のまとまりがどのようにつながって語られていたかなどが示されています。
また、比較対象となるデータがある場合には、論の構成の比較を行うこともできます。例えば、スティーブ・ジョブズの講演と自分のスピーチを比較して、どこが似ていて、どこを直せばより近づけるのかといった解析をすることも可能です。
| 論理構造図(解析図) | 話題のつながりや話題ごとの情報量の過不足が可視化できる解析図 |
|---|---|
| 総合スコア | 「論理性」「納得させやすさ」「話題の密度」「対策の充実度」などの項目ごとにスコアリングしたもの |
| 論の構成グラフ | データベース平均・所属部署平均などとの比較ができるレーダーチャート |
| 論の展開傾向 | 「連結直線」「連結分岐」「単独分岐」「大循環」「小循環」の五つの傾向のうち、どこが強く出ていたのかの分析 |
| 重要論点ランキング | 特に重要な話題・分岐点となった論点のランキングおよび全体の要約 |
| 要検討箇所のランキング | 重要な論点であるにもかかわらず、検討が不十分で聞き手に納得してもらえない可能性が高い論点のランキング |
| 事実情報一覧 | データや事例など、事実に基づいた情報を提供している話題の一覧 |
| 話題のまとまり一覧 | 話題のまとまりをキーワードで示し、俯瞰できるようにした図 |
| 議事録 | 話の内容の議事録と、解析ルールに基づく話題ごとの分類 |
どのように解析を行っているのでしょうか。
解析の基本となっているルールは、イギリスの哲学者スティーヴン・トゥールミン(Stephen Edelston Toulmin: 1922-2009)によって提唱された論証モデルである「トゥールミンモデル(Toulmin's Argument Model )」をベースに、弊社が独自に生み出したものです。
主張の論理性を高めるためには、主張に正当性があると示すことができ、かつ量的にも十分と考えられるデータや事実、裏付けなどが必要です。トゥールミンはこれらを定義づけて明文化し、論証モデルをつくりました。
しかし、トゥールミンモデルはベーシックな文法に基づく文章には適用させやすいものの、会話や講演といった話し言葉の表現には応用が難しい部分もありました。会話をする場面を思い浮かべていただくとわかりやすいのですが、話す内容というのは、必ずしも論理的で起承転結がしっかり整っているわけではありません。時には同じ内容を何度も繰り返すことや、ブレインストーミングのように話が飛躍して新しいアイデアが出ることに意義がある場合もあります。
そのため弊社ではまず、書き言葉・話し言葉を問わず「すべての表現」を再現する、情報の形式表現ルールをつくることにしました。さまざまなデータをトゥールミンモデルに当てはめた時、どのようなデータがルールから外れてしまうのか、そのデータにも当てはまるようにするにはルールをどう変更すればいいのかを、一つひとつ検証していったのです。
こうして書き言葉でも話し言葉でも当てはまる表現ルールを作った後に、そのルールで分類したデータをデータベースに入力していきました。現在では4000以上の会話や講演のデータを蓄積しており、より正確な解析を行うことが可能になっています。
■分析レポートでわかるもの(以下の項目は代表的なものであり、解析対象によって異なる)
最初に解析ルールを設定するというのは面白い手法ですね。なぜこのようなアプローチで解析を行おうと考えたのでしょうか。
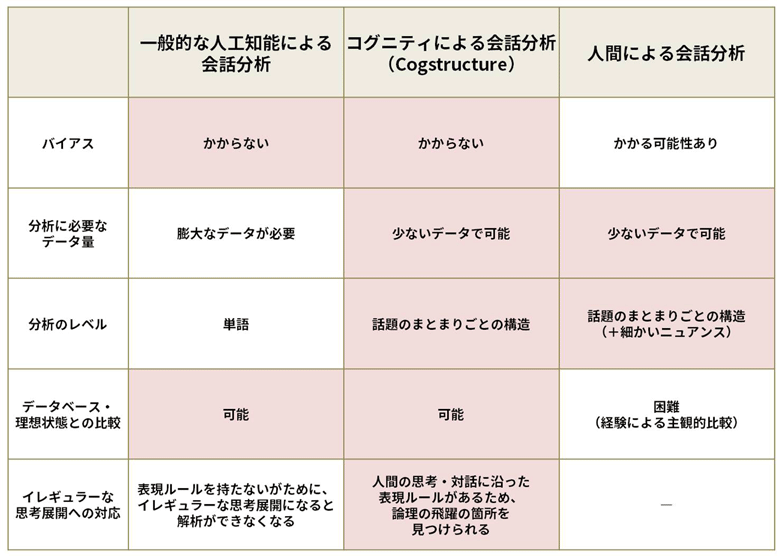
通常、「人工知能」と聞いた時に思い浮かべられる解析のアプローチは、取り込んだ膨大なデータを、ニューラルネットワークや深層学習(ディープラーニング)によって処理するというものです。
この解析方法には、二つの課題があります。まずは、解析には膨大な会話のデータが必要となること。さらに、一般的な人工知能は本来、囲碁や将棋など、明確なルールが定まっているものの解析を得意としており、会話のように例外の多いものはミスが出やすくなってしまうことです。
これらの課題に対して、書き言葉・話し言葉すべてに当てはまる一定のルールをあらかじめ設定していれば、それに沿ったかたちで傾向を探すことができ、変則的な内容が含まれていたとしても、より少ない情報で解析することができるのです。




